Process groups, jobs and sessions #
Contents
- Process groups
- Sessions
- Controlling terminal, controlling process, foreground and background process groups
- Shell job control
killcommand- Terminating shell
nohupanddisown- Daemons
A new process group is created every time we execute a command or a pipeline of commands in a shell. Inside a shell, a process group is usually called a job. In its turn, each process group belongs to a session. Linux kernel provides a two-level hierarchy for all running processes (look at figure 3 below). As such, a process group is a set of processes, and a session is a set of related process groups. Another important limitation is that a process group and its members can be members of a single session.
$ sleep 100 # a process group with 1 process
$ cat /var/log/nginx.log | grep string | head # a process group with 3 processes
Process groups #
A process group has its process group identificator PGID and a leader who created this group. The PID of the group leader is equal to the corresponding PGID. As so, the type of PID and PGID are the same, and is (pid_t)[https://ftp.gnu.org/old-gnu/Manuals/glibc-2.2.3/html_node/libc_554.html]. All new processes created by the group members inherit the PGID and become the process group members. In order to create a group, we have setpgid() and setpgrp() syscalls (man 2 getpgrp()).
A process group lives as long as it has at least one member. It means that even if the group leader terminates, the process group is valid and continues carrying out its duties. A process can leave its process group by:
- joining another group;
- creating its own new group;
- terminating.
Linux kernel can reuse PIDs for new processes if only the process group with that PGID doesn’t have members. It secures a valid hierarchy of processes.
Two interesting features of process groups are:
- a parent process can
wait()for its children using the process group id; - a signal can be sent to all members of a process group by using
killpg()orkill()with a negativePGIDparameter.
The below command sends a SIGTERM(15) to all members of the process group 123:
$ kill -15 -123
The following 2 scripts demonstrate this feature. We have 2 long-running scripts in a process group (it was created for us automatically by shell) connected by a pipe.
print.py
import signal
import os
import sys
import time
def signal_handler(signum, frame):
print(f"[print] signal number: {signum}", file=sys.stderr)
os._exit(signum)
signal.signal(signal.SIGTERM, signal_handler)
print(f"PGID: {os.getpgrp()}", file=sys.stderr)
for i in range(9999):
print(f"{i}")
sys.stdout.flush()
time.sleep(1)
and
stdin.py
import fileinput
import signal
import os
import sys
def signal_handler(signum, frame):
print(f"[stdin] signal number: {signum}", file=sys.stderr)
os._exit(signum)
signal.signal(signal.SIGTERM, signal_handler)
for i, line in enumerate(fileinput.input()):
print(f"{i+1}: {line.rstrip()}")
Start the pipeline, and in the middle of the execution, run a kill command in a new terminal window.
$ python3 ./print.py | python3 ./stdin.py
PGID: 9743
1: 0
2: 1
3: 2
4: 3
[stdin] signal number: 15
[print] signal number: 15
And kill it by specifying the PGID:
$ kill -15 -9743
Sessions #
For its part, a session is a collection of process groups. All members of a session identify themselves by the identical SID. It’s also the pid_t type, and as a process group, also inherited from the session leader, which created the session. All processes in the session share a single controlling terminal (we’ll talk about this later).
A new process inherits its parent’s session ID. In order to start a new session a process should call setsid() (man 2 setsid). The process running this syscall begins a new session, becomes its leader, starts a new process group, and becomes its leader too. SID and PGID are set to the process’ PID. That’s why the process group leader can’t start a new session: the process group could have members, and all these members must be in the same session.
Basically, a new session is created in two cases:
- When we need to log in a user with an interactive shell. A shell process becomes a session leader with a controlling terminal (about this later).
- A daemon starts and wants to run in its own session in order to secure itself (we will touch daemons in more detail later).
The following image shows a relationship between a session, its process groups and processes.
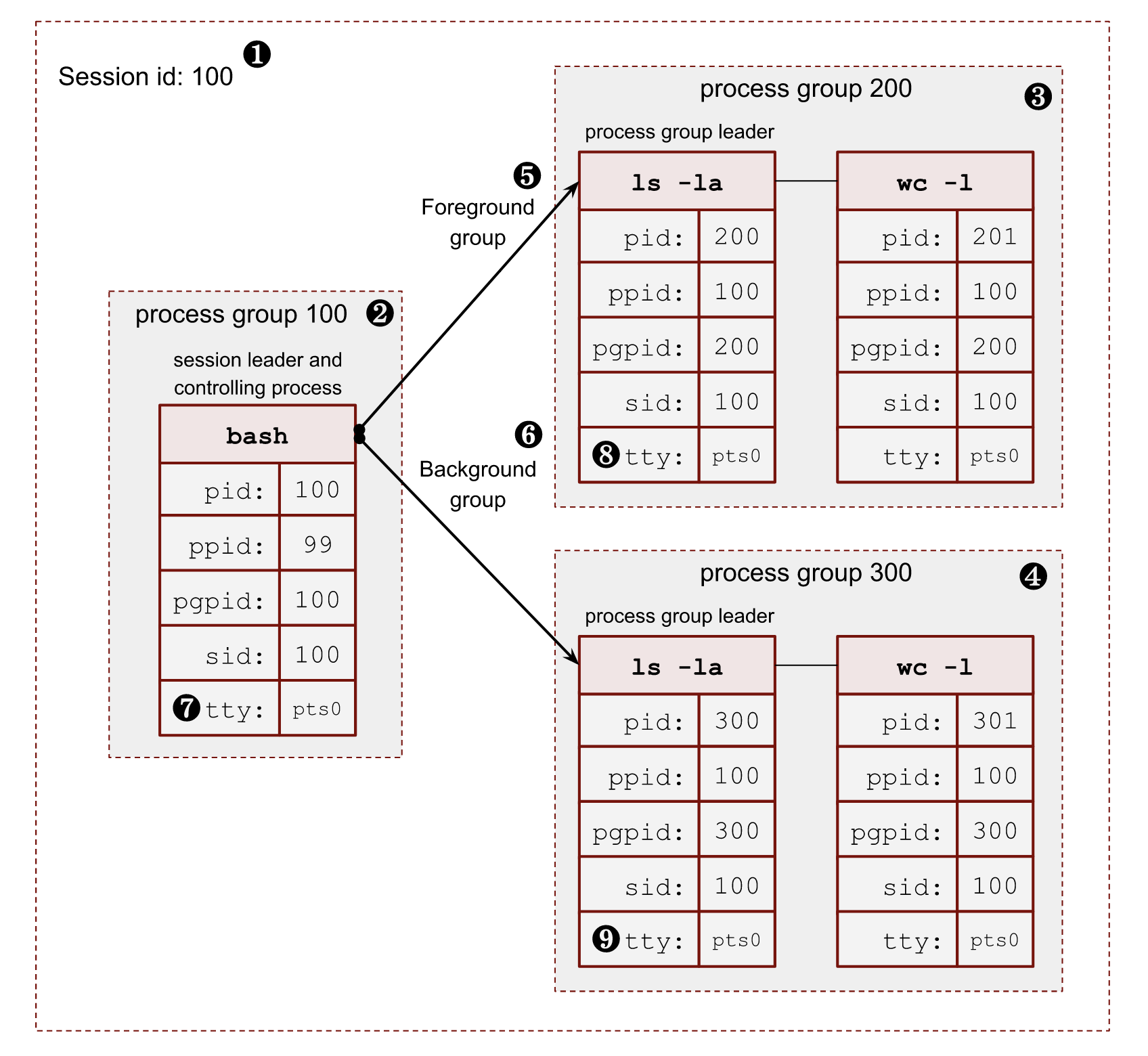
- ❶ – Session id (
SID) is the same as the session leader process (bash)PID. - ❷ – The session leader process (
bash) has its own process group, where it’s a leader, soPGIDis the same as itsPID. - ❸, ❹ – The session has 2 more process groups with
PGIDs 200 and 300. - ❺, ❻ – Only one group can be a foreground for a terminal. All other process groups are background. We will touch on these terms in a minute.
- ❼, ❽, ❾ – All members of a session share a pseudoterminal
/dev/pts/0.
In order to get all the above information for a running process, we can read the /proc/$PID/stat file. For example, for my running bash shell $$ porcess:
$ cat /proc/$$/stat | cut -d " " -f 1,4,5,6,7,8 | tr ' ' '\n' | paste <(echo -ne "pid\nppid\npgid\nsid\ntty\ntpgid\n") -
pid 8415 # PID
ppid 8414 # parent PID
pgid 8415 # process group ID
sid 8415 # sessions ID
tty 34816 # tty number
tpgid 9348 # foreground process group ID
where (man 5 procfs https://man7.org/linux/man-pages/man5/proc.5.html):
pid– the process id.ppid– thePIDof the parent of this process.pgrp– the process group id of the process.sid– the session id of the process.tty– the controlling terminal of the process. (The minor device number is contained in the combination of bits 31 to 20 and 7 to 0; the major device number is in bits 15 to 8.)tpgid– the id of the foreground process group of the controlling terminal of the process.
Controlling terminal, controlling process, foreground and background process groups #
A controlling terminal is a terminal (tty, pty, console, etc) that controls a session. There may not be a controlling terminal for a session. It is usual for daemons.
In order to create a controlling terminal, at first, the session leader (usually a shell process) starts a new session with setsid(). This action drops a previously available terminal if it exists. Then the process needs to open a terminal device. On this first open() call, the target terminal becomes the controlling terminal for the session. From this point in time, all existing processes in the session are able to use the terminal too. The controlling terminal is inherited by fork() call and preserved by execve(). A particular terminal can be the controlling terminal only for one session.
A controlling terminal sets 2 important definitions: a foreground process group and a background process group. At any moment, there can be only one foreground process group for the session and any number of background ones. Only processes in the foreground process group can read from the controlling terminal. On the other hand, writes are allowed from any process by default. There are some tricks with terminals, we touch them later, when we will talk solely about terminals.
A terminal user can type special signal-generating terminal characters on the controlling terminal. The most famous ones are CTRL+C and CTRL+Z. As its name suggests, a corresponding signal is sent to the foreground process group. By default, the CTRL+C triggers a SIGINT signal, and CTRL+Z a SIGTSTP signal.
Also, opening the controlling terminal makes the session leader the controlling process of the terminal. Starting from this moment, if a terminal disconnection occurs, the kernel will send a SIGHUP signal to the session leader (usually a shell process).
The tcsetpgrp() (man 3 tcsetpgrp) is a libc function to promote a process group to the foreground group of the controlling terminal. There is also the tcgetpgrp() function to get the current foreground group. These functions are used primarily by shells in order to control jobs. On linux, we can also use ioctl() with TIOCGPGRP and TIOCSPGRP operations to get and set the foreground group.
Let’s write a script that emulates the shell logic of creating a process group for a pipeline.
pg.py
import os
print(f"parent: {os.getpid()}")
pgpid = os.fork() # ⓵
if not pgpid:
# child
os.setpgid(os.getpid(), os.getpid()) # ⓶
os.execve("./sleep.py", ["./sleep.py", ], os.environ)
print(f"pgid: {pgpid}")
pid = os.fork()
if not pid:
# child
os.setpgid(os.getpid(), pgpid) # ⓷
os.execve("./sleep.py", ["./sleep.py", ], os.environ)
pid = os.fork()
if not pid:
# child
os.setpgid(os.getpid(), pgpid) # ⓷
os.execve("./sleep.py", ["./sleep.py", ], os.environ)
for i in range(3) :
pid, status = os.waitpid(-1, 0)
⓵ – Create the first process in the shell pipeline.
⓶ – Start a new process group and store its PID as a new PGID for all future processes.
⓷ – Start new processes and move them into the process group with PGID.
So when we run it we can see the following output:
python3 ./pg.py
parent: 8429
pgid: 8430
8431 sleep
8432 sleep
8430 sleep
The full state of processes:
$ cat /proc/8429/stat | cut -d " " -f 1,4,5,6,7,8 | tr ' ' '\n' | paste <(echo -ne "pid\nppid\npgid\nsid\ntty\ntpgid\n") -
pid 8429
ppid 8415
pgid 8429
sid 8415
tty 34816
tpgid 8429
$ cat /proc/8430/stat | cut -d " " -f 1,4,5,6,7,8 | tr ' ' '\n' | paste <(echo -ne "pid\nppid\npgid\nsid\ntty\ntpgid\n") -
pid 8430
ppid 8429
pgid 8430
sid 8415
tty 34816
tpgid 8429
$ cat /proc/8431/stat | cut -d " " -f 1,4,5,6,7,8 | tr ' ' '\n' | paste <(echo -ne "pid\nppid\npgid\nsid\ntty\ntpgid\n") -
pid 8431
ppid 8429
pgid 843
sid 8415
tty 34816
tpgid 8429
$ cat /proc/8432/stat | cut -d " " -f 1,4,5,6,7,8 | tr ' ' '\n' | paste <(echo -ne "pid\nppid\npgid\nsid\ntty\ntpgid\n") -
pid 8432
ppid 8429
pgid 8430
sid 8415
tty 34816
tpgid 8429
The only problem with the above code is we didn’t transfer the foreground group to our newly created process group. The tpgid in the above output shows that. The 8429 PID is a PGID of the parent pg.py script, not the newly created process group 8430.
Now, if we press CTRL+C to terminate the processes, we’ll stop only the parent with PID 8429. It happens because it’s in the foreground group from the perspective of the controlling terminal. All processes in the 8430 group will continue running in the background. If they try to read from the terminal (stdin), they will be stopped by the controlling terminal by sending them a SIGTTIN signal. It is a result of trying to read from the controlling terminal without acquiring the foreground group. If we log out or close the controlling terminal, this group will not get a SIGHUP signal, because the bash process (the controlling process) doesn’t know that we started something in the background.
In order to fix this situation, we need to notify the controlling terminal that we want to run another process group in the foreground. Let’s modify the code and add the tcsetpgrp() call.
import os
import time
import signal
print(f"parent: {os.getpid()}")
pgpid = os.fork()
if not pgpid:
# child
os.setpgid(os.getpid(), os.getpid())
os.execve("./sleep.py", ["./sleep.py", ], os.environ)
print(f"pgid: {pgpid}")
pid = os.fork()
if not pid:
# child
os.setpgid(os.getpid(), pgpid)
os.execve("./sleep.py", ["./sleep.py", ], os.environ)
pid = os.fork()
if not pid:
# child
os.setpgid(os.getpid(), pgpid)
os.execve("./sleep.py", ["./sleep.py", ], os.environ)
tty_fd = os.open("/dev/tty", os.O_RDONLY) # ⓵
os.tcsetpgrp(tty_fd, pgpid) # ⓶
for i in range(3): # ⓷
os.waitpid(-1, 0)
h = signal.signal(signal.SIGTTOU, signal.SIG_IGN) # ⓸
os.tcsetpgrp(tty_fd, os.getpgrp()) # ⓹
signal.signal(signal.SIGTTOU, h) # ⓺
print("got foreground back")
time.sleep(99999)
⓵ – In order to run the tcsetpgrp(), we need to know the current controlling terminal path. The safest way to do that is to open a special virtual file /dev/tty. If a process has a controlling terminal, it returns a file descriptor for that terminal. We, in theory, can use one of the standard file descriptors too. But it’s not sustanable because the caller can redirects all of them.
⓶ – Put the new process group into the foreground group of the controlling terminal.
⓷ – Here, we wait for the processes to exit. It is where we should call CTRL+C.
⓸ – Before we command the controlling terminal to return into the foreground session we need to silence the SIGTTOU signal. The man page says: If tcsetpgrp() is called by a member of a background process group in its session, and the calling process is not blocking or ignoring SIGTTOU, a SIGTTOU signal is sent to all members of this background process group. We don’t need this signal, so it’s OK to block it.
⓹ – Returning to the foreground.
⓺ – Restoring the SIGTTOU signal handler.
And if we now run the script and press CTRL+C, everything should work as expected.
$ python3 ./pg.py
parent: 8621
pgid: 8622
8622 sleep
8624 sleep
8623 sleep
^C <------------------- CTRL+C was pressed
Traceback (most recent call last):
File "/home/vagrant/data/blog/post2/./sleep.py", line 7, in <module>
Traceback (most recent call last):
File "/home/vagrant/data/blog/post2/./sleep.py", line 7, in <module>
Traceback (most recent call last):
File "/home/vagrant/data/blog/post2/./sleep.py", line 7, in <module>
time.sleep(99999)
KeyboardInterrupt
time.sleep(99999)
KeyboardInterrupt
time.sleep(99999)
KeyboardInterrupt
got foreground back <----------------- back to foreground
Shell job control #
Now it’s time to understand how shells allow us to run multiple commands simultaneously and how we can control them.
For instance, when we run the following pipeline:
$ sleep 999 | grep 123
The shell here:
- creates a new process group with the
PGIDof the first process in the group; - puts this group in the foreground group by notifying the terminal with
tcsetpgrp(); - stores the
PIDs and sets up awaitpid()syscall.
The process group is also known as a shell job.
The PIDs:
$ ps a | grep sleep
9367 pts/1 S+ 0:00 sleep 999
$ ps a | grep grep
9368 pts/1 S+ 0:00 grep 123
And if we get the details for sleep:
$ cat /proc/9367/stat | cut -d " " -f 1,4,5,6,7,8 | tr ' ' '\n' | paste <(echo -ne "pid\nppid\npgid\nsid\ntty\ntpgid\n") -
pid 9367
ppid 6821
pgid 9367
sid 6821
tty 34817
tpgid 9367
and for grep:
$ cat /proc/9368/stat | cut -d " " -f 1,4,5,6,7,8 | tr ' ' '\n' | paste <(echo -ne "pid\nppid\npgid\nsid\ntty\ntpgid\n") -
pid 9368
ppid 6821
pgid 9367
sid 6821
tty 34817
tpgid 9367
While waiting for the foreground job to finish, we can move this job to the background by pressing Ctrl+Z. It is a control action for the terminal, which sends a SIGTSTP signal to the foreground process group. The default signal handler for a process is to stop. In its turn, bash gets a notification from the waitpid(), that the statuses of the monitoring processes have changed. When bash sees that the foreground group has become stopped, it returns the foreground back to shell by running tcsetpgrp():
^Z
[1]+ Stopped sleep 999 | grep 123
$
We can get the current statuses of all known jobs by using the built-in jobs command:
$ jobs -l
[1]+ 7962 Stopped sleep 999
7963 | grep 123
We may resume a job in the background by calling bg shell built-in with the ID of the job.When we use bg with a background stopped job, the shell uses killpg and SIGCONT signal.
$ bg %1
[1]+ sleep 999 | grep 123 &
If we check the status now, we can see that it’s running in the background.
$ jobs -l
[1]+ 7962 Running sleep 999
7963 | grep 123 &
If we want, we can move the job back in the foreground by calling fg built-in shell command:
$ fg %1
sleep 999 | grep 123
We also can start a job in the background by adding an ampersand (&) char in the end of the pipeline:
$ sleep 999 | grep 123 &
[1] 9408
$
kill command
#
kill is usually a shell built-in for at least two reasons:
- Shell usually allows to kill jobs by their job ids. So we need to be able to resolve internal job IDs into process group IDs (the
%job_idsyntaxis). - Allow users to send signals to processes if the system hits the max running process limit. Usually, during emergencies and system misbehaviour.
For example, we can check how bash does it – int kill_builtin() and zsh – int bin_kill().
Another helpful piece of knowledge about the kill command and system calls is a “-1” process group. It’s a special group, and the signal to it will fan out the signal to all processes on the system except the PID 1 process (it’s almost always a systemd process on all modern GNU/Linux distributions):
[remote ~] $ sudo kill -15 -1
Connection to 192.168.0.1 closed by remote host.
Connection to 192.168.0.1 closed.
[local ~] $
Terminating shell #
When a controlling process loses its terminal connection, the kernel sends a SIGHUP signal to inform it of this fact. If either the controlling process or other members of the session ignores this signal, or handle it and do nothing, then the further read from and write to the closed terminal (ususally /dev/pts/*) calls will return the end-of-file (EOF) zero bytes.
Shell processes (which are usually control terminals) have a handler to catch SIGHUP signals. Receiving a signal starts a fan-out process of sending SIGHUP signals to all jobs it has created and know about (remember the fg, bg and waitpid()). The default action for the SIGHUP is terminate.
nohup and disown
#
But suppose we want to protect our long-running program from being suddenly killed by a broken internet connection or low laptop battery. In that case, we can start a program under nohup tool or use bash job control disownbuilt-in command. Let’s understand how they work and where they are different.
The nohup performs the following tricks:
- Changes the
stdinfd to/dev/null. - Redirects the
stdoutandstderrto a file on disk. - Set an ignore
SIG_IGNflag forSIGHUPsignal. The interesting moment here is that theSIG_IGNis preserved after theexecve()syscall. - Run the
execve().
All the above make the program immune to the SIGHUP signal and can’t fail due to writing to or reading from the closed terminal.
$ nohup ./long_running_script.py &
[1] 9946
$ nohup: ignoring input and appending output to 'nohup.out'
$ jobs -l
[1]+ 9946 Running nohup ./long_running_script.py &
As you can see from the output, the bash knows about this process and can show it in jobs.
Another way we have to achieve long-running programs to survive the controlling terminal closure is a built-in disown of the bash shell. Instead of ignoring the SIGHUP signal, it just removes the job’s PID from the list of known jobs. Thus no SIGHUP signal will be sent to the group.
$ ./long_running_script.py &
[1] 9949
$ jobs -l
[1]+ 9949 Running ./long_running_script.py &
$ disown 9949
$ jobs -l
$ ps a | grep 9949
9949 pts/0 S 0:00 /usr/bin/python3 ./long_running_script.py
9954 pts/0 S+ 0:00 grep 9949
The drawback of the above solution is we don’t overwrite and close the terminal standard fd. So if the tool decides to write to or read from the closed terminal, it could fail.
The other conclusion we can make is that the shell doesn’t send SIGHUP to processes or groups it did not create, even if the process is in the same session where the shell is a session leader.
Daemons #
A daemon is a long living process. It is often started at the system’s launch and service until the OS shutdown. Daemon runs in the background without a controlling terminal. The latest guarantees that the process never gets terminal-related signals from the kernel: SIGINT, SIGTSTP, and SIGHUP.
The classic “unix” way of spawning daemons is performed by a double-fork technique. After both fork() calls the parents exit immediately.
- The first
fork()is needed:- to become a child of the
systemdprocess withPID1; - if a daemon starts manually from a terminal, it puts itself into the background and a shell doesn’t know about it, so it can’t terminate the daemon easily;
- the child is guaranteed not to be a process group leader, so the following
setsid()call starts a new session and breaks a possible connection to the existing controlling terminal.
- to become a child of the
- The second
fork()is done in order to stop being the session leader. This step protects a daemon from opening a new controlling terminal, as only a session leader can do that.
The gnu provides a convininet libc function to demonize our program: daemon() man 3 daemon.
But nowadays, systems with systemd tend not to follow the double-fork trick. Instead developers highly rely on systemd features:
systemdcan starts a new process session for daemons;- it can swap the standard file descriptors for
stdin,stdoutandstderrwith regular files or sockets instead of manually close or redirect them tosyslog. For examplenginxcode:
...
fd = open("/dev/null", O_RDWR);
...
if (dup2(fd, STDIN_FILENO) == -1) {
ngx_log_error(NGX_LOG_EMERG, log, ngx_errno, "dup2(STDIN) failed");
return NGX_ERROR;
}
...
So, a daemon can continue safely write to the stderr and stdout and don’t be afraid of getting the EOF because of a closed terminal. The following setting controls that:
StandardOutput=
StandardError=
For instance, etcd service doesn’t do a double-fork and fully rely on the systemd. That’s why its PID is a PGID and SID, so it’s a session leader.
$ cat /proc/10350/stat | cut -d " " -f 1,4,5,6,7,8 | tr ' ' '\n' | paste <(echo -ne "pid\nppid\npgid\nsid\ntty\ntpgid\n") -
pid 10350
ppid 1
pgid 10350
sid 10350
tty 0
tpgid -1
Also systemd has a lot of other features for modern service developers such as helpers for live upgrades, socket activation, sharing sockets, cgroup limits, etc…