Essential Page Cache theory #
Contents
First of all, let’s start with a bunch of reasonable questions about Page Cache:
- What is the Linux Page Cache?
- What problems does it solve?
- Why do we call it «Page» Cache ?
In essence, the Page Cache is a part of the Virtual File System (VFS) whose primary purpose, as you can guess, is improving the IO latency of read and write operations. A write-back cache algorithm is a core building block of the Page Cache.
NOTE
If you’re curious about the write-back algorithm (and you should be), it’s well described on Wikipedia, and I encourage you to read it or at least look at the figure with a flow chart and its main operations.
“Page” in the Page Cache means that linux kernel works with memory units called pages. It would be cumbersome and hard to track and manage bites or even bits of information. So instead, Linux’s approach (and not only Linux’s, by the way) is to use pages (usually 4K in length) in almost all structures and operations. Hence the minimal unit of storage in Page Cache is a page, and it doesn’t matter how much data you want to read or write. All file IO requests are aligned to some number of pages.
The above leads to the important fact that if your write is smaller than the page size, the kernel will read the entire page before your write can be finished.
The following figure shows a bird’s-eye view of the essential Page Cache operations. I broke them down into reads and writes.
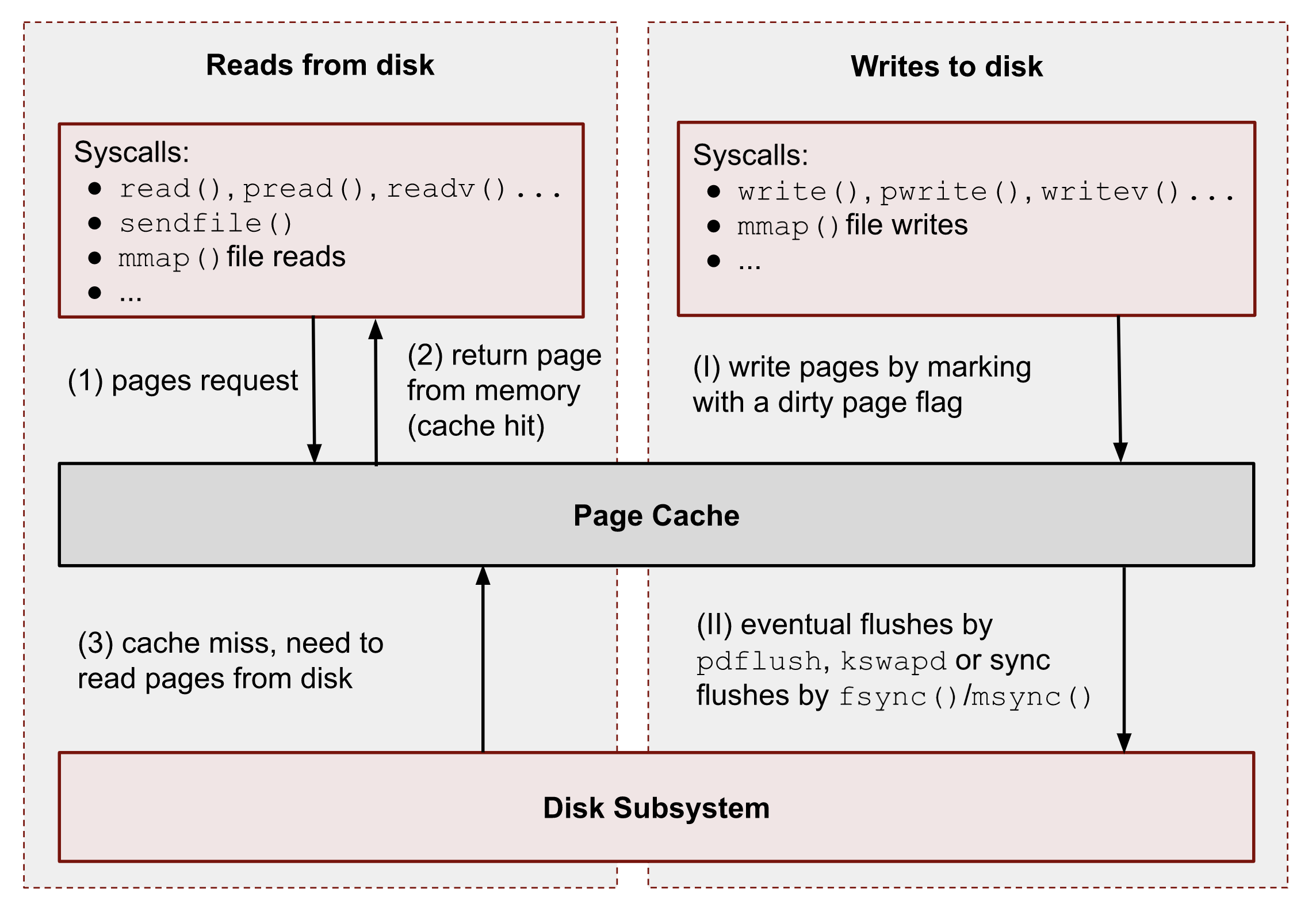
As you can see, all data reads and writes go through Page Cache. However, there are some exceptions for Direct IO (DIO), and I’m talking about it at the end of the series. For now, we should ignore them.
NOTE
In the following chapters, I’m talking about
read(),write(),mmap()and other syscalls. And I need to say, that some programming languages (for example, Python) have file functions with the same names. However, these functions don’t map exactly to the corresponding system calls. Such functions usually perform buffered IO. Please, keep this in mind.
Read requests #
Generally speaking, reads are handled by the kernel in the following way:
① – When a user-space application wants to read data from disks, it asks the kernel for data using special system calls such as read(), pread(), vread(), mmap(), sendfile(), etc.
② – Linux kernel, in turn, checks whether the pages are present in Page Cache and immediately returns them to the caller if so. As you can see kernel has made 0 disk operations in this case.
③ – If there are no such pages in Page Cache, the kernel must load them from disks. In order to do that, it has to find a place in Page Cache for the requested pages. A memory reclaim process must be performed if there is no free memory (in the caller’s cgroup or system). Afterward, kernel schedules a read disk IO operation, stores the target pages in the memory, and finally returns the requested data from Page Cache to the target process. Starting from this moment, any future requests to read this part of the file (no matter from which process or cgroup) will be handled by Page Cache without any disk IOP until these pages have not been evicted.
Write requests #
Let’s repeat a step-by-step process for writes:
(Ⅰ) – When a user-space program wants to write some data to disks, it also uses a bunch of syscalls, for instance: write(), pwrite(), writev(), mmap(), etc. The one big difference from the reads is that writes are usually faster because real disk IO operations are not performed immediately. However, this is correct only if the system or a cgroup doesn’t have memory pressure issues and there are enough free pages (we will talk about the eviction process later). So usually, the kernel just updates pages in Page Cache. it makes the write pipeline asynchronous in nature. The caller doesn’t know when the actual page flush occurs, but it does know that the subsequent reads will return the latest data. Page Cache protects data consistency across all processes and cgroups. Such pages, that contain un-flushed data have a special name: dirty pages.
(II) – If a process’ data is not critical, it can lean on the kernel and its flush process, which eventually persists data to a physical disk. But if you develop a database management system (for instance, for money transactions), you need write guarantees in order to protect your records from a sudden blackout. For such situations, Linux provides fsync(), fdatasync() and msync() syscalls which block until all dirty pages of the file get committed to disks. There are also open() flags: O_SYNC and O_DSYNC, which you also can use in order to make all file write operations durable by default. I’m showing some examples of this logic later.