Page Cache eviction and page reclaim #
Contents
- Essesntial theory
- Manual pages eviction with
POSIX_FADV_DONTNEED - Make your memory unevictable
- Page Cache,
vm.swappinessand modern kernels - Understanding memory reclaim process with
/proc/pid/pagemap
So far, we have talked about adding data to Page Cache by reading and writing files, checking the existence of files in the cache, and flushing the cache content manually. But the most crucial part of any cache system is its eviction policy, or regarding Linux Page Cache, it’s also the memory page reclaim policy. Like any other cache, Linux Page Cache continuously monitors the last used pages and makes decisions about which pages should be deleted and which should be kept in the cache.
The primary approach to control and tune Page Cache is the cgroup subsystem. You can divide the server’s memory into several smaller caches (cgroups) and thus control and protect applications and services. In addition, the cgroup memory and IO controllers provide a lot of statistics that are useful for tuning your software and understanding the internals of the cache.
Theory #
Linux Page Cache is closely tightened with Linux Memory Management, cgroup and virtual file system (VFS). So, in order to understand how eviction works, we need to start with some basic internals of the memory reclaim policy. Its core building block is a per cgroup pair of active and inactive lists:
- the first pair for anonymous memory (for instance, allocated with
malloc()or not file backendedmmap()); - the second pair for Page Cache file memory (all file operations including
read(),write, filemmap()accesses, etc.).
The former is exactly what we are interested in. This pair is what linux uses for Page Cache evection process. The least recently used algorithm LRU is the core of each list. In turn, these 2 lists form a double clock data structure. In general, Linux should choose pages that have not been used recently (inactive) based on the fact that the pages that have not been used recently will not be used frequently in a short period of time. It is the basic idea of the LRU algorithm. Both the active and the inactive lists adopt the form of FIFO (First In First Out) for their entries. New elements are added to the head of the linked list, and the elements in between gradually move toward the end. When memory reclamation is needed, the kernel always selects the page at the end of the inactive list for releasing. The following figure shows the simplified concept of the idea:
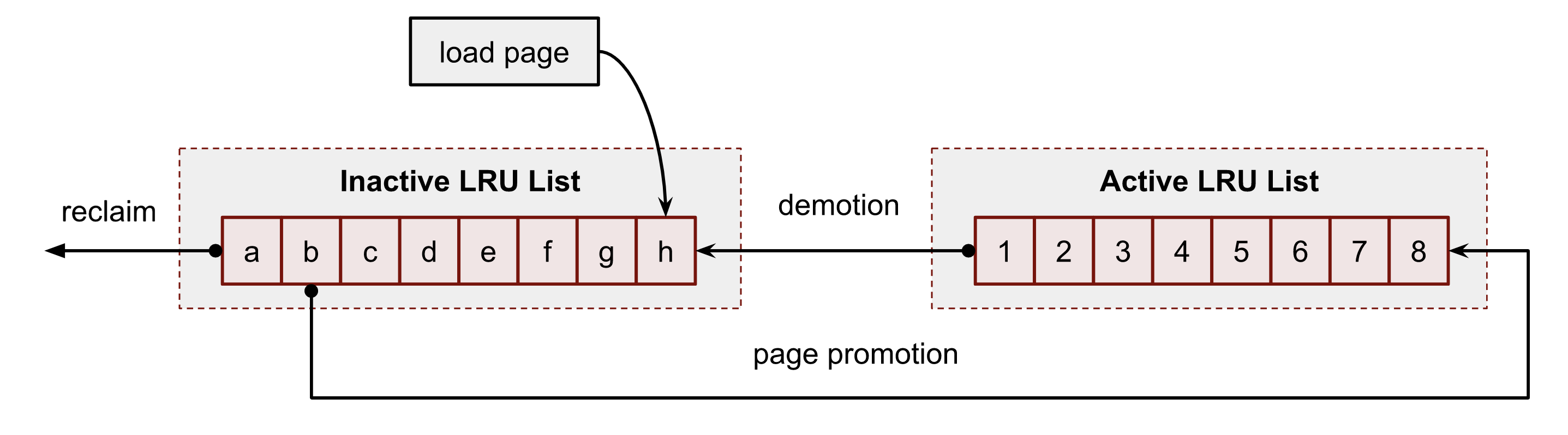
For example, the system starts with the following content of the lists. A user process has just read some data from disks. This action triggered the kernel to load data to the cache. It was the first time when the kernel had to access the file. Hence it added a page h to the head of the inactive list of the process’s cgroup:

Some time has passed, and the system loads 2 more pages: i and j to the inactive list and accordingly has to evict pages a and b from it. This action also shifts all pages toward the tail of the inactive LRU list, including our page h:

Now, a new file operation to the page h promotes the page to the active LRU list by putting it at the head. This action also ousts the page 1 to the head of the inactive LRU list and shifts all other members.

As time flies, page h looses its head position in the active LRU list.

But a new file access to the h’s position in the file returns h back to the head of the active LRU list.

The above figures show the simplified version of the algorithm.
But it’s worth mentioning that the real process of pages promotion and demotion is much more complicated and sophisticated.
First of all, if a system has NUMA hardware nodes (man 8 numastat), it has twice more LRU lists. The reason is that the kernel tries to store memory information in the NUMA nodes in order to have fewer lock contentions.
In addition, Linux Page Cache also has special shadow and referenced flag logic for promotion, demotion and re-promotion pages.
Shadow entries help to mitigate the memory thrashing problem. This issue happens when the programs’ working set size is close to or greater than the real memory size (maybe cgroup limit or the system RAM limitation). In such a situation, the reading pattern may evict pages from the inactive list before the subsequent second read request has appeared. The full idea is described in the mm/workingset.c and includes calculating refault distance. This distance is used to judge whether to put the page from the shadow entries immediately to the active LRU list.
Another simplification I made was about PG_referenced page flag. In reality, the page promotion and demotion use this flag as an additional input parameter in the decision algorithm. A more correct flow of the page promotion:
flowchart LR A[Inactive LRU,\nunreferenced] --> B[Inactive LRU,\nreferenced] B --> C[Active LRU,\nunreferenced] C --> D[Active LRU,\nreferenced]
Manual pages eviction with POSIX_FADV_DONTNEED
#
I’ve already shown how to drop all Page Cache entries using /proc/sys/vm/drop_caches file. But what if we want for some reason to clear the cache for a file?
EXAMPLE
It could sometimes be useful to evict a file from the cache in a real life situation. Assume we want to test how fast our MongoDB gets back to optimal condition after a system reboot. You can stop a replica, clean all its files from Page Cache and start it back.
vmtouch already can do that. Its -e flag commands the kernel to evict all pages of the requested file from Page Cache:
For example:
$ vmtouch /var/tmp/file1.db -e
Files: 1
Directories: 0
Evicted Pages: 32768 (128M)
Elapsed: 0.000704 seconds
$ vmtouch /var/tmp/file1.db
Files: 1. LOOK HERE
Directories: 0 ⬇
Resident Pages: 0/32768 0/128M 0%
Elapsed: 0.000566 seconds
Let’s look under the hood and figure out how it works. In order to write our own tool we need to use the already seen posix_fadvise syscall with the POSIX_FADV_DONTNEED option.
Code:
import os
with open("/var/tmp/file1.db", "br") as f:
fd = f.fileno()
os.posix_fadvise(fd, 0, os.fstat(fd).st_size, os.POSIX_FADV_DONTNEED)
For testing, I read the entire test file into Page Cache with dd:
$ dd if=/var/tmp/file1.db of=/dev/null
262144+0 records in
262144+0 records out
134217728 bytes (134 MB, 128 MiB) copied, 0.652248 s, 206 MB/s
$ vmtouch /var/tmp/file1.db
Files: 1 LOOK HERE
Directories: 0 ⬇
Resident Pages: 32768/32768 128M/128M 100%
Elapsed: 0.002719 seconds
And now, after running our script, we should see 0 pages in Page Cache:
$ python3 ./evict_full_file.py
$ vmtouch /var/tmp/file1.db
Files: 1 LOOK HERE
Directories: 0 ⬇
Resident Pages: 0/32768 0/128M 0%
Elapsed: 0.000818 seconds
Make your memory unevictable #
But what if you want to force the kernel to keep your file memory in Page Cache, no matter what. It is called making the file memory unevictable .
EXAMPLE
Sometimes you have to force the kernel to give you a 100% guarantee that your files will not be evicted from the memory. You can want it even with modern linux kernels and properly configured cgroup limits, which should keep the working data set in Page Cache. For example, due to issues with other processes on the system where you share disk and network IO. Or, for instance, because of an outage of a network attached storage.
Kernel provides a bunch of syscalls for doing that: mlock(), mlock2() and mlockall(). As with the mincore(), you must map the file first.
mlock2() is a preferable syscall for Page Cache routines because it has the handy flag MLOCK_ONFAULT:
Lock pages that are currently resident and mark the entire range so that the remaining nonresident pages are locked when they are populated by a page fault.
And don’t forget about limits (man 5 limits.conf). You likely need to increased it:
$ ulimit -l
64
And finally, to get the amount of unevictable memory, please, check the cgroup memory controller stats for your cgroup:
$ grep unevictable /sys/fs/cgroup/user.slice/user-1000.slice/session-3.scope/memory.stat
unevictable 0
Page Cache, vm.swappiness and modern kernels
#
Now that we understand the basic reclaiming theory with 4 LRU lists (for anon and file memory) and evictable/unevictable types of memory, we can talk about the sources to refill the system free memory. The kernel constantly maintains lists of free pages for itself and user-space needs. If such lists get below the threshold, the linux kernel starts to scan LRU lists in order to find pages to reclaim. It allows the kernel to keep memory in some equilibrium state.
The Page Cache memory is usually evictable memory (with some rare mlock() exceptions). And thus, it maybe look obvious, that Page Cache should be the first and the only option for the memory eviction and reclaiming. Since disks already have all that data, right? But fortunately or unfortunately, in real production situations, this is not always the best choice.
If the system has swap (and it should have it with modern kernels), the kernel has one more option. It can swap out the anonymous (not file-backed) pages. It may seem counterintuitive, but the reality is that sometimes user-space daemons can load tons of initialization code and never use it afterward. Some programs, especially statically built, for example, could have a lot of functionality in their binaries that may be used only several times in some edge cases. In all such situations, there is not much sense in keeping them in valuable memory.
So, in order to control which inactive LRU list to prefer for scans, the kernel has the sysctl vm.swappiness knob.
$ sudo sysctl -a | grep swap
vm.swappiness = 60
There are a lot of blog posts, stories and forum threads about this magic setting. On top of that, the legacy cgroup v1 memory subsystem has its own per cgroup swappiness knob. All this makes information about the current vm.swappiness meaning hard to understand and change. But let me try to explain some recent changes and give you fresh links.
First of all, by default vm.swappiness is set 60, the min is 0 and the max is 200:
/*
* From 0 .. 200. Higher means more swappy.
*/
int vm_swappiness = 60;
The 100 value means that the kernel considers anonymous and Page Cache pages equally in terms of reclamation.
Secondly, the cgroup v2 memory controller doesn’t have the swappiness knob at all:
#ifdef CONFIG_MEMCG
static inline int mem_cgroup_swappiness(struct mem_cgroup *memcg)
{
/* Cgroup2 doesn't have per-cgroup swappiness */
if (cgroup_subsys_on_dfl(memory_cgrp_subsys))
return vm_swappiness;
/* root ? */
if (mem_cgroup_disabled() || mem_cgroup_is_root(memcg))
return vm_swappiness;
return memcg->swappiness;
Instead, the kernel developers decided to change the swappiness logic significantly. You can check it if you run git blame on mm/vmscan.c and search for the get_scan_count() function.
For example, at the time of writing, the anonymous memory will not be touched regardless of vm.swappiness if the inactive LRU Page Cache list has a decent amount of pages:
/*
* If there is enough inactive page cache, we do not reclaim
* anything from the anonymous working right now.
*/
if (sc->cache_trim_mode) {
scan_balance = SCAN_FILE;
goto out;
}
The full logic of making decisions about what and from which LRU to reclaim, you can find in the get_scan_count()function in mm/vmscan.c.
Also, please take a look at the memory.swap.high and the memory.swap.max cgroup v2 settings. You can control them if you want to correct the vm.swappiness logic for your cgroup and load pattern.
Another interesting topic, which you should keep in mind when dealing with the swap and Page Cache, is the IO load during the swapping in/out processes. If you have IO pressure, you can easily hit your IO limits and, for example, degrade your Page Cache writeback performance.
Understanding memory reclaim process with /proc/pid/pagemap
#
Now it’s time for low level troubleshooting technics.
There is a /proc/PID/pagemap file that contains the page table information of the PID. The page table, basically speaking, is an internal kernel map between page frames (real physical memory pages stored in RAM) and virtual pages of the process. Each process in the linux system has its own virtual memory address space which is completely independent form other processes and physical memory addresses.
The full /proc/PID/pagemap and related file documentation, including data formats and ways to read, it can be found in the kernel documentation folder. I strongly recommend that you read it before proceeding to the sections below.
page-types kernel page tool
#
page-types is the Swiss knife of every kernel memory hacker. Its source code comes with the Linux kernel sources tools/vm/page-types.c.
If you didn’t install it in the first chapter:
$ wget https://github.com/torvalds/linux/archive/refs/tags/v5.13.tar.gz
$ tar -xzf ./v5.13.tar.gz
$ cd v5.13/vm/tools
$ make
Now let’s use it in order to understand how many pages of our test file /var/tmp/file1.db the kernel has placed in Active and Inactive LRU lists:
$ sudo ./page-types --raw -Cl -f /var/tmp/file1.db
foffset cgroup offset len flags
/var/tmp/file1.db Inode: 133367 Size: 134217728 (32768 pages)
Modify: Mon Aug 30 13:14:19 2021 (13892 seconds ago)
Access: Mon Aug 30 13:15:47 2021 (13804 seconds ago)
10689 @1749 21fa 1 ___U_lA_______________________P____f_____F_1
...
18965 @1749 24d37 1 ___U_l________________________P____f_____F_1
18966 @1749 28874 1 ___U_l________________________P____f_____F_1
18967 @1749 10273 1 ___U_l________________________P____f_____F_1
18968 @1749 1f6ad 1 ___U_l________________________P____f_____F_1
flags page-count MB symbolic-flags long-symbolic-flags
0xa000010800000028 105 0 ___U_l________________________P____f_____F_1 uptodate,lru,private,softdirty,file,mmap_exclusive
0xa00001080000002c 16 0 __RU_l________________________P____f_____F_1 referenced,uptodate,lru,private,softdirty,file,mmap_exclusive
0xa000010800000068 820 3 ___U_lA_______________________P____f_____F_1 uptodate,lru,active,private,softdirty,file,mmap_exclusive
0xa001010800000068 1 0 ___U_lA_______________________P____f_I___F_1 uptodate,lru,active,private,softdirty,readahead,file,mmap_exclusive
0xa00001080000006c 16 0 __RU_lA_______________________P____f_____F_1 referenced,uptodate,lru,active,private,softdirty,file,mmap_exclusive
total 958 3
The output contains 2 sections: the first one provides per-page information, and the second aggregates all pages with the same flags and counts the summary. What we need from the output in order to answer to the LRU question are A and l flags, which, as you can guess, stand for “active” and “inactive” lists.
As you can see, we have:
105 + 16 = 121 pagesor121 * 4096 = 484 KiBin inactive LRU list.820 + 1 + 16 = 837 pagesor837 * 4096 = 3.2 MiBin active LRU list.
Writing Page Cache LRU monitor tool #
page-types is a really useful tool for low-level debugging and investigations, but its output format is hard to read and aggregate. I promised earlier that we would write our own vmtouch, so now we’re creating it. Our alternative version will provide even more information about pages. It will show not only how many pages are in Page Cache, but also how many of them are in the active and the inactive LRU lists.
To do this, we need 2 kernel files: /proc/PID/pagemap and /proc/kpageflags.
The full code you can find in the github repo, however here, I would like to focus on a few important moments:
...
① err = syscall.Madvise(mm, syscall.MADV_RANDOM)
...
② ret, _, err := syscall.Syscall(syscall.SYS_MINCORE, mmPtr, sizePtr, cachedPtr)
for i, p := range cached {
③ if p%2 == 1 {
④ _ = *(*int)(unsafe.Pointer(mmPtr + uintptr(pageSize*int64(i))))
}
}
...
⑤ err = syscall.Madvise(mm, syscall.MADV_SEQUENTIAL)
...
- ① – Here, we need to disable the read ahead logic for the target file in order to protect ourselves from loading (charging) unneeded data to Page Cache by our tool;
- ② – Use
mincore()syscall to get a vector of the pages in Page Cache; - ③ – Here, we check whether a page is in Page Cache or not;
- ④ – If Page Cache contains a page, we need to update the corresponding process’s page table entry by referencing this page. Our tool has to do this in order to use the
/proc/pid/pagemap. Otherwise the/proc/pid/pagemapfile will not contain the target file pages and thus their flags. - ⑤ – Here, we are turning off the harvesting of reference bits. This is required due to kernel reclaim logic. Our tool read memory and hence influences the kerne LRU lists. By using
madvise()withMADV_SEQUENTIALwe notify linux kernel to ignore our operations.
Let’s test our tool. We need 2 terminals. In the first one, start our tool with watch (man 1 watch) to run our tool every 100ms in an infinitive loop:
watch -n 0.1 'sudo go run ./lru.go'
And in the second terminal, we will read the file with the dd (man 1 dd):
dd if=/var/tmp/file1.db of=/dev/null
Demo of what you should see:
Using the above approach, you can now perform low-level Page Cache investigations.
Read next chapter →